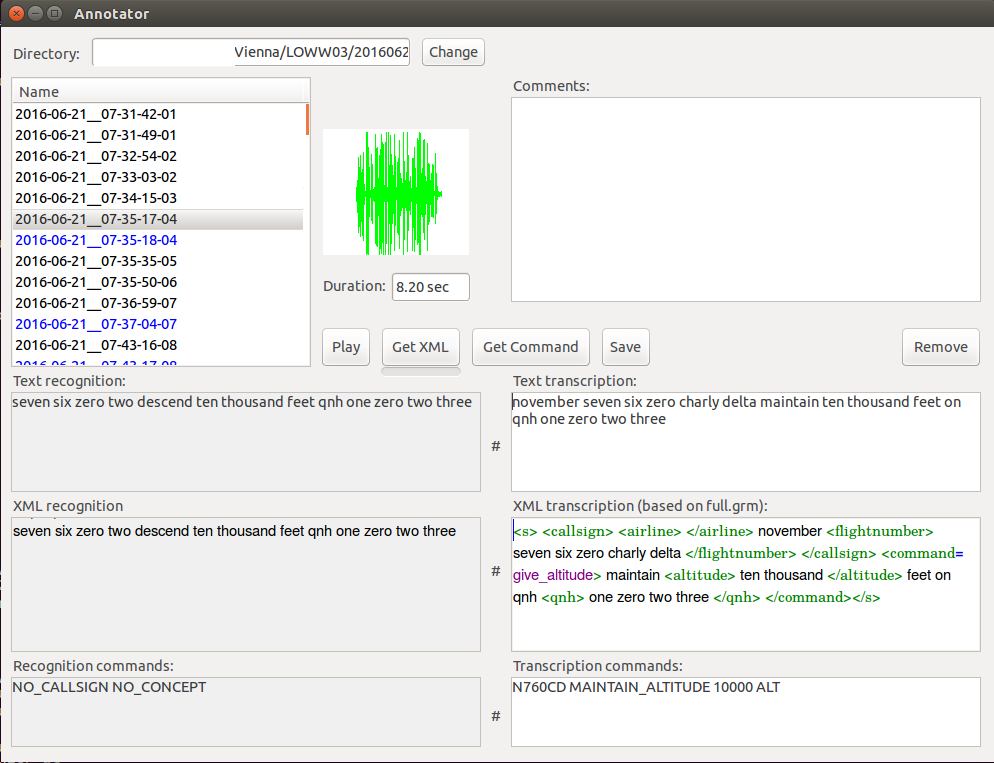
Machine learning algorithms require large amounts of speech and the corresponding radar data samples from live traffic, especially in unsupervised adaptation and self learning scenarios. 10 hours of transcribed and 100 hours of untranscribed data is being collected in Vienna and Prague. The transcription process is highly automatized and builds upon the knowledge acquired during the AcListant® project. This already makes it possible to extract constraints from radar data (called context) which can be applied in automatic speech recognition of the utterances. In this way, so-called pre-transcriptions are generated automatically. A special and easy-to-use annotator tool with a GUI provides facilities to check – and if necessary – to correct these pre-transcriptions manually.
The textual transcription is further processed into a rich XML transcription, where entities (words or phrases) informative with respect to air traffic controller commands are tagged. This level of the transcription is closely linked to the language model (or grammar) used by the Assistance Based Speech Recognition (ABSR) system to define the phraseology (inventory of possible pronunciations of all commands). The tagged entities are called concepts. A concept can be an action required by the command (e.g.. turn), or attributes of the command (value, e.g. 30 degrees, left) for example. Finally, concepts build up a command. The future goal of MALORCA is to let the system learn how it can identify and extract concepts itself from controller utterances without human intervention and hence reconstruct a command in a formal level.
These goals require the usage of exhaustive unsupervised techniques at all levels of the ABSR: acoustic model adaptation, language model adaptation, context extraction from radar data and concept generation. The datasets under construction are designed to fulfill these needs and make possible the application of data demanding machine learning approaches. The models used for pre-transcription are coming from a first iteration of adaptation on the ABSR available from AcListant®. The goal of MALORCA that after a minimal human intervention specifying airport specific entities (such as waypoints, radar frequencies…), the system iteratively adapts itself to the environment it is used within.