MALORCA (Machine Learning of Speech Recognition Models for Controller Assistance) covers a 24 months period and started in April 2016 with a kick-off meeting at the Braunschweig site of DLR.
The projects AcListant® and AcListant®-Strips have demonstrated that controllers can be supported by Assistant Based Speech Recognition (ABSR) with command error rates below 2%. ABSR uses speech recognition embedded in a controller assistant system, which provides a dynamic minimized world model to the speech recognizer. The speech recognizer and the assistant system improve each other. The latter significantly reduces the search space of the first one, resulting in low command recognition error rates. However, transferring the developed ABSR prototype to different operational environments, i.e. different approach areas, can be very expensive, because the system requires adaptation to specific local needs such as speaker accents, special airspace characteristics, or local deviations from ICAO standard phraseology. The goal of this project is to solve these issues by a machine learning approach to provide a cheap, efficient and reliable process for a successful deployment of Assistance Based Speech Recognition (ABSR) systems for ATC tasks, from the laboratory to the real world.
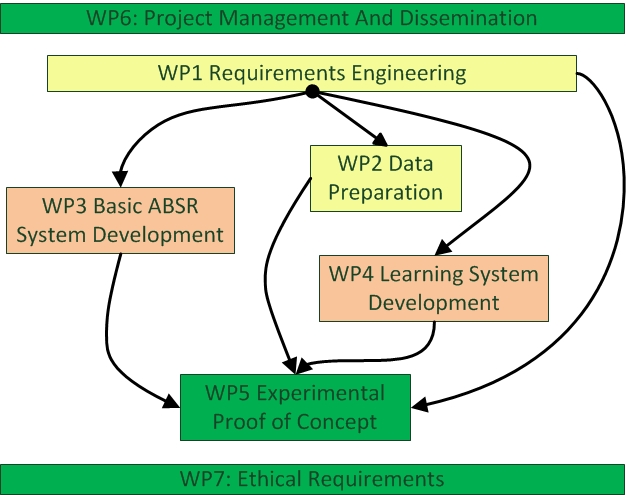
The project is divided into 5 main work packages (WP1-5) and the project management and dissemination in work package WP6 respectively the Ethical Requirements in WP7. The project starts in WP1 with analyzing the requirements with respect to the users’ needs and especially with respect to data availability, in order to deliver other WPs with clear, coherent, and well-established requirements that act as essential building blocks for all the defined modules. WP1 will also elaborate on the compliance with the ethical standards to guarantee protection of personal data.
WP2 will be responsible for delivering a first set of target-data (real speech recordings from air traffic controllers) for both selected approach areas (i.e. Prague and Vienna). In a first iteration, approximately 10 hours of real-time controller voice communication together with the associated metadata (contextual information from different sensors) will be provided. A fully manual pre-segmentation and transcription will be performed on that data.
In WP3 the specific knowledge suitable only for AcListant® end-users (airport of Dusseldorf) will be removed and the respective modules will be manually adapted to Vienna and Prague approach (test sites of this project). Afterwards the transcribed data from WP2, enriched with interviews provided by ANSP (ACG and ANS-CR), will be used to build an initial assistant based automatic speech recognizer (ABSR-0) for a generic approach area together with an integrated basic recognition model.
The ABSR-0 will represent the starting point of WP4. A significant amount of training data (approximately 100 hours of speech recordings) will be provided by the two ANSPs each together with the associated context information from other sensors. In contrast to WP2 the speech recordings will not be transcribed manually. WP4 will instead rely on methods of unsupervised learning and data mining to automatically generate an improved recognition model.
WP5 will be related to the experimental proof of concept. As controllers are end users of speech recognition, their feedback is essential. WP5 will, therefore, start with speech recordings (controller voice communication) together with the associated context for both approach areas. These data sets will not be used by the WP4 learning algorithms; instead they will serve as evaluation data. The controllers will be integrated into the feedback process by presenting their own speech recordings together with the radar data to them. The controller will listen to the communication and will evaluate ABSR performance. In parallel the speech recordings will also be manually transcribed, so that objective recognition accuracy will be available.